Echomimic V2免安装环境版
更新: 12/21/2024 字数: 0 字 时长: 0 分钟
概述
EchoMimic是由阿里巴巴蚂蚁集团推出的一款开源AI数字人项目,它通过先进的深度学习技术,将静态图像转化为具有动态语音和表情的数字人像。这项技术的核心在于它能够根据音频输入,实时生成与语音同步的口型和面部表情,从而创造出逼真的动态肖像视频。
配置要求
- 对显卡配置较高,
RTX4090在20步,生成10秒视频大约需要10分钟,低显存或低配置可能需要时间较长 12G显存以上英伟达显卡- 推荐
768x768尺寸
整体流程
EchoMimicV2 利用参考图像、音频片段和一系列手势来生成高质量的动画视频,确保音频内容和半身动作之间的连贯性。 为了弥补半身数据的稀缺,利用头部部分注意力将头像数据无缝地容纳到训练框架中,这些数据可以在推理过程中被省略。
此外,还设计了阶段特定的去噪损失,分别来指导特定阶段动画的运动、细节和低级质量。此外还提出了一个用于评估半身人体动画效果的新基准。大量实验和分析表明,EchoMimicV2 在定量和定性评估方面均超越了现有方法。
V1版介绍
- V1仅用图片和音频生成数字脸,V2就是真正的数字人了。一张半身照片,配上中文或英语音频,就能生成带手势的数字人视频

功能
- 音频同步动画 EchoMimic的音频同步动画功能是其最引人注目的特点之一。通过深度分析音频波形,系统能够精确捕捉语音的节奏、音调、强度等关键特征,并实时生成与语音同步的口型和面部表情。这项功能使得静态图像能够展现出与真实人类几乎无异的动态表现。
- 面部特征融合 面部特征融合技术是EchoMimic的另一项核心优势。项目采用面部标志点技术,通过高精度的面部识别算法,捕捉眼睛、鼻子、嘴巴等关键部位的运动,并将这些特征融合到动画中,极大地增强了动画的真实感和表现力。
- 多模态学习 EchoMimic的多模态学习能力体现在它能够同时处理音频和视觉数据。系统通过深度学习模型,将这两种类型的数据进行有效整合,提升了动画的自然度和表现力,使得生成的动画在视觉上和语义上都能与音频内容高度一致。
- 跨语言能力 EchoMimic支持中文普通话和英语等多种语言,这使得不同语言区域的用户都能利用该技术制作动画。跨语言能力不仅拓宽了EchoMimic的应用范围,也为多语言环境下的数字人像生成提供了可能。
- 风格多样性 EchoMimic能够适应不同的表演风格,无论是日常对话、歌唱还是其他形式的表演,都能通过相应的参数调整来实现。这种风格多样性为用户提供了广泛的应用场景,满足了不同用户的需求。
使用说明
项目信息
项目主页:地址
模型下载
通过HuggingFace下载:地址
通过魔塔下载:地址
paper
arxiv: 点击访问
常见问题

正确使用方法
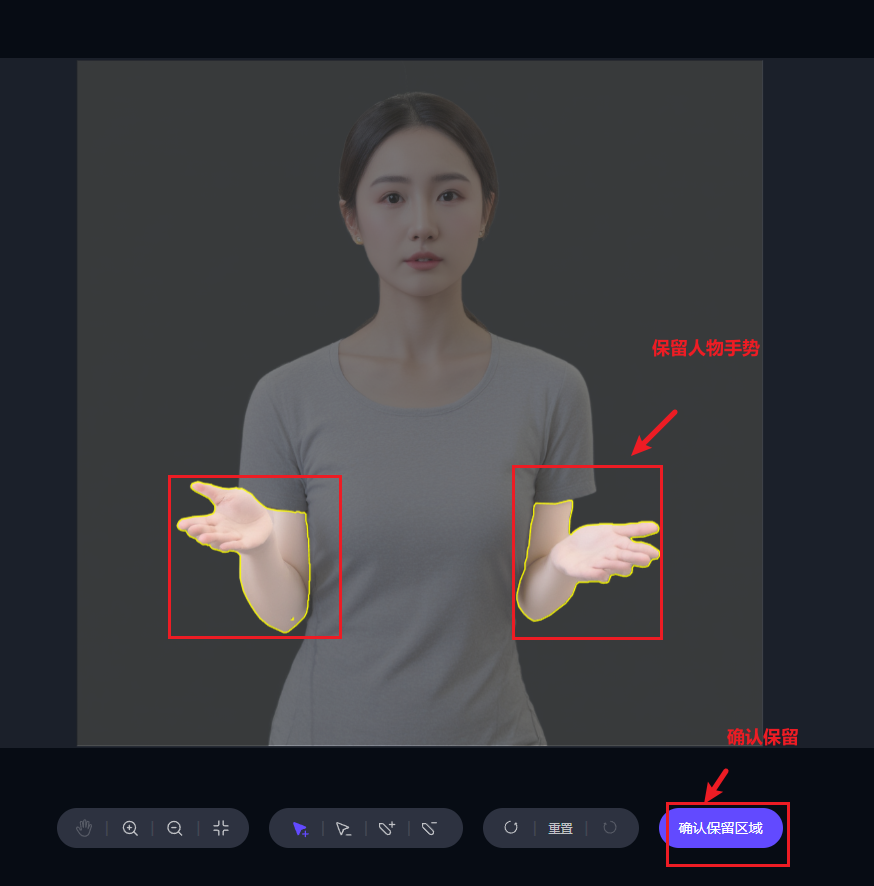
生成正确含手势模特图片
注意事项
- 图片背景尽量简单,
- 人物必须包含人手手势(截至2024-12-01,否则生成人物可能会变形)
- 以下是几种免费的生成模特图片的方式
参考图

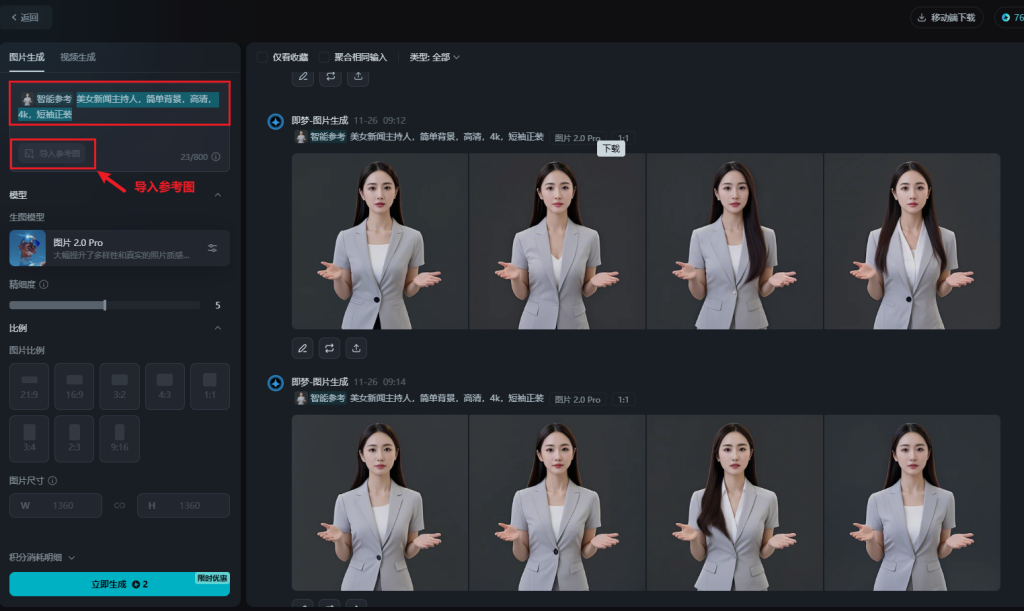
方式1:使用即梦生成
参考提示词
美女新闻主持人,简单背景,高清,4k,短袖正装
- 使用即梦 –>
AI作图–>图片生成,输入提示词,根据参考图,生成模特图片
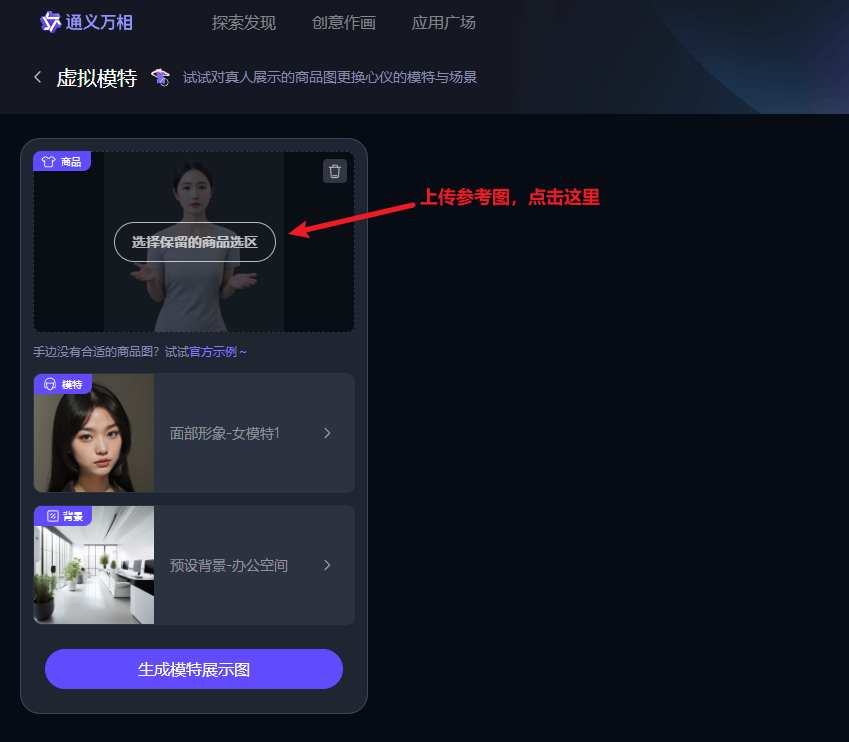
方式2:使用通义生成
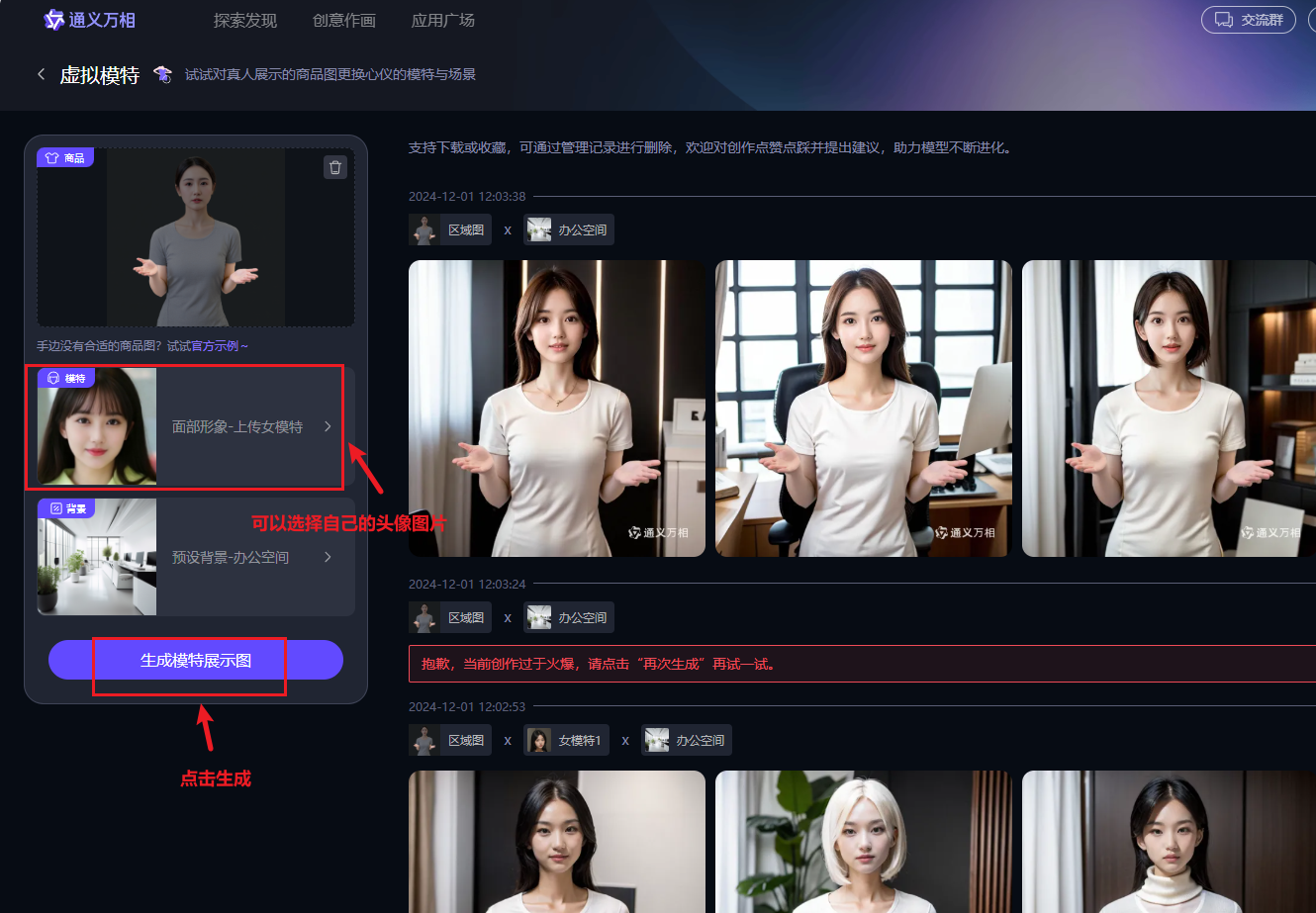
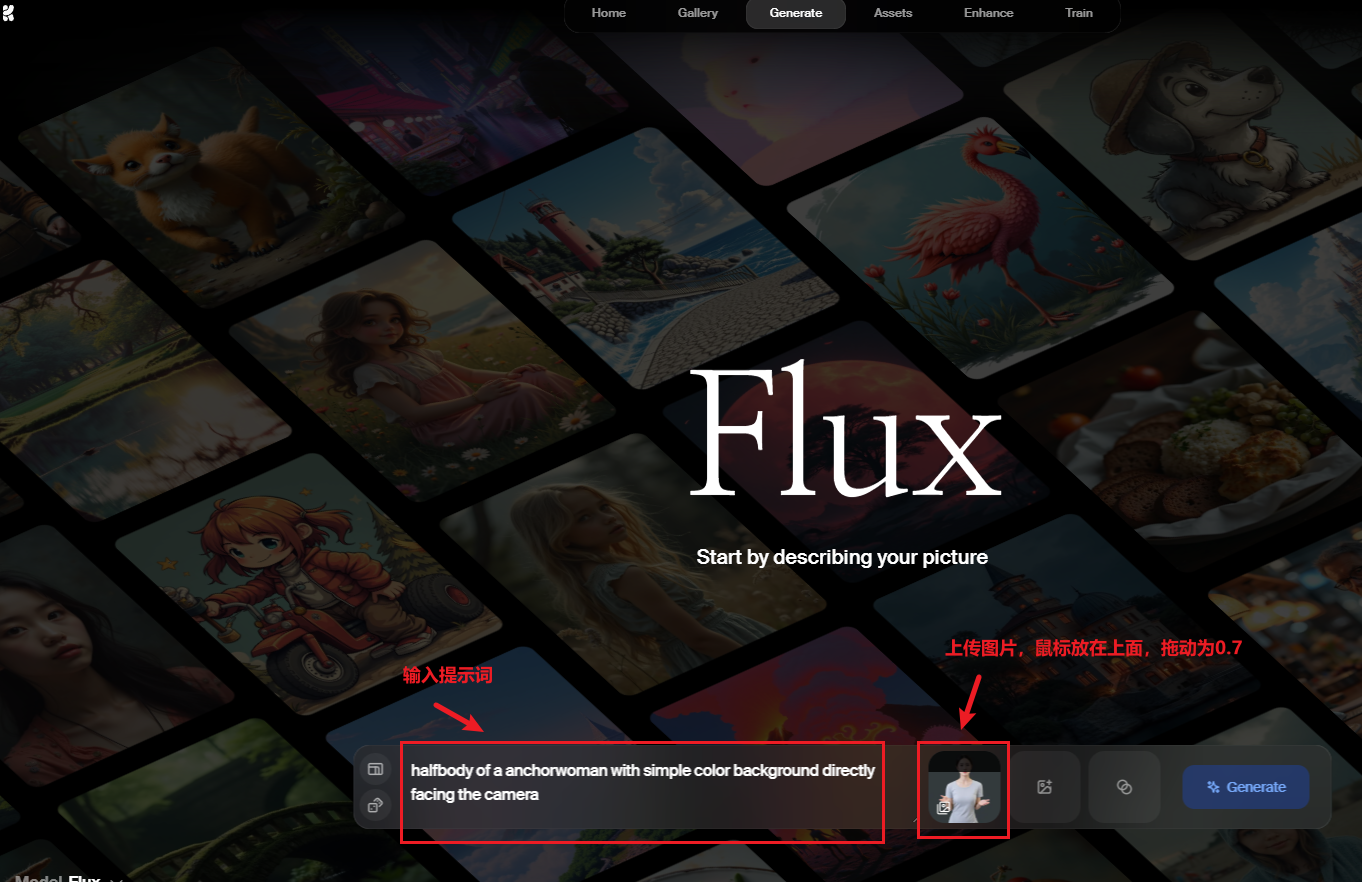
方式3:krea.ai生成
参考提示词
halfbody of a anchorwoman with simple color background directly facing the camera
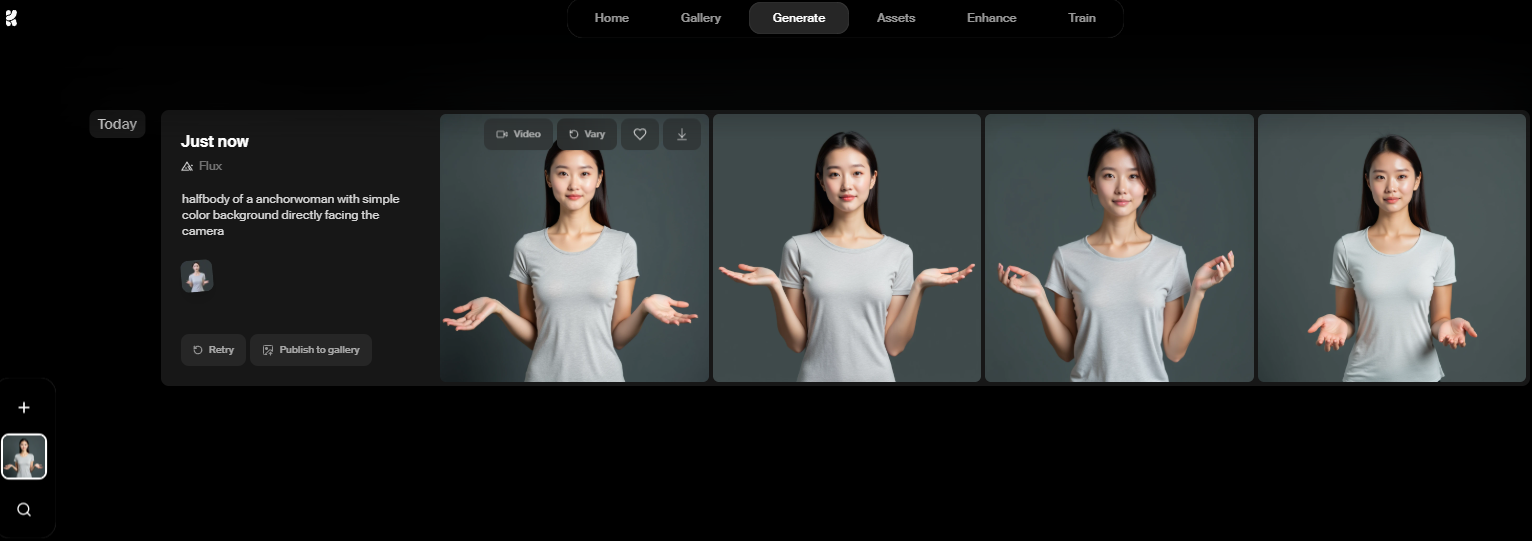
免安装环境241122-webui版 ✅
注意
解压后,路径不要含有中文,路径不要含有中文,路径不要含有中文
下载说明
- 软件已经过测试,测试平台为
Windows10和Nvidia-4090显卡 - 不支持
AMD显卡及核显,显存尽量大于12GB,cuda-12版本,低显存或低cuda版本不保证正常使用 - 点此查看自己的显卡相关信息
- 压缩包已包含依赖的环境模型等大文件,无需安装环境,点开即用;
- 大小:14GB
下载地址
运行说明
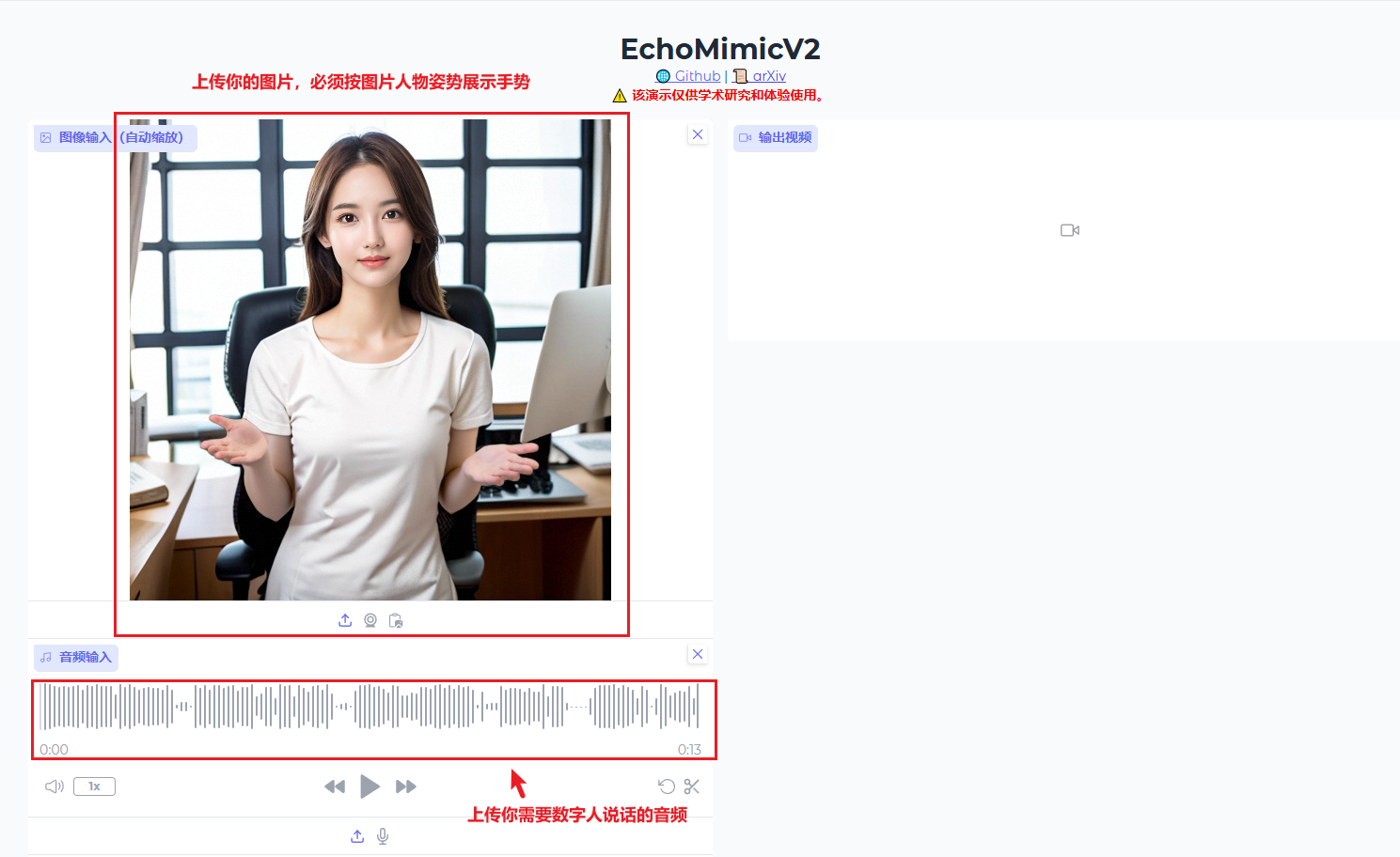
- 图片尺寸必须为16的整数倍(例如:512×512,768×768),
尽量半身照,姿势和表情参考如下测试图片 - 测试使用
RTX4090,生成10s音频为演示用(便于用户根据自身配置比较) - 低显存或普通配置用户,尽量每次音频不超过
5s,并勾选int8选项 RTX4090生成10s音频需要10分钟左右
运行
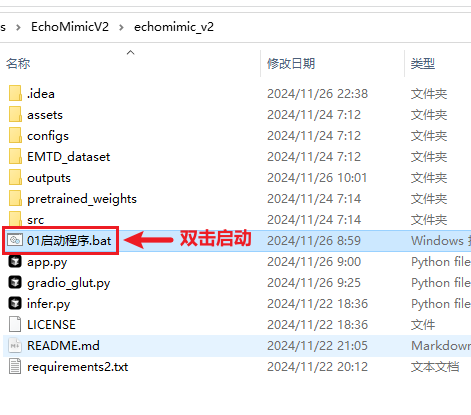
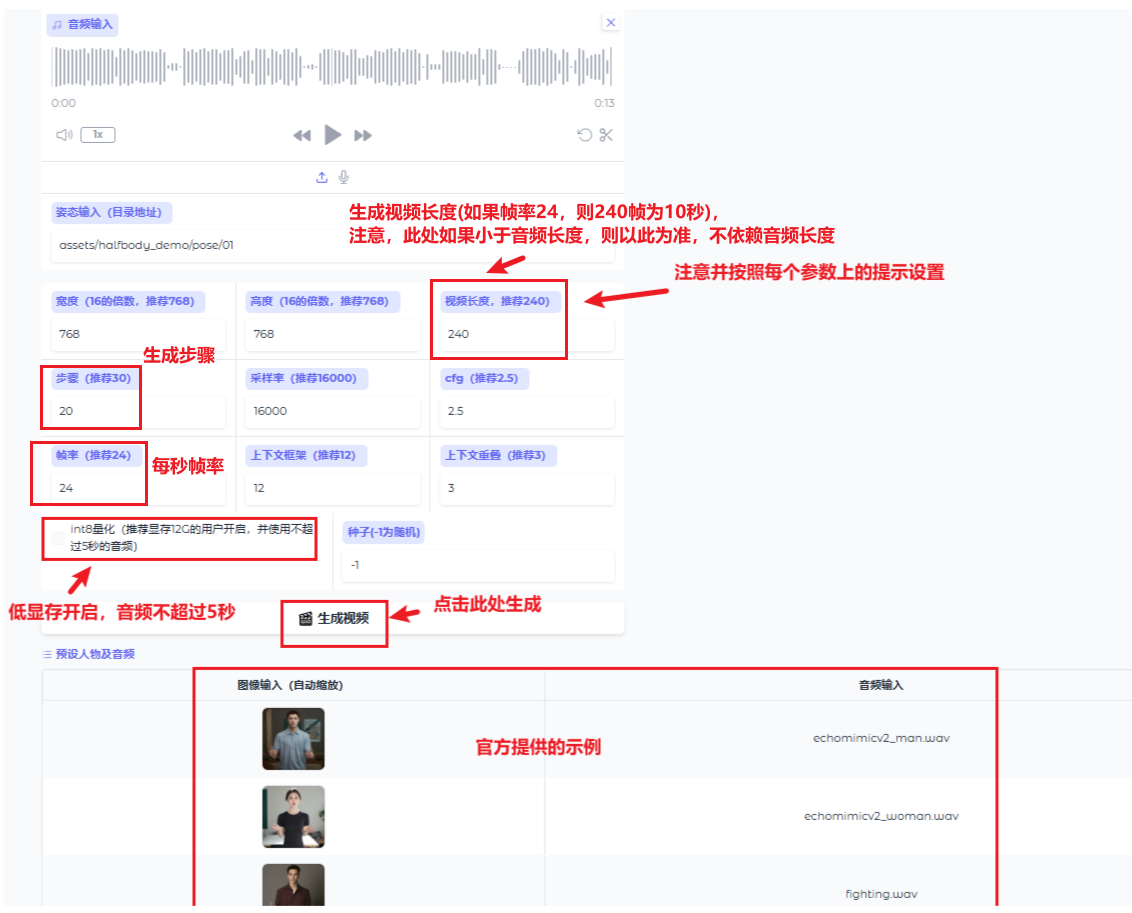
- 10s左右音频,20步(可配置),每步大约30秒,总共大约需10分钟(不同显卡配置,时间不同,仅供参考)
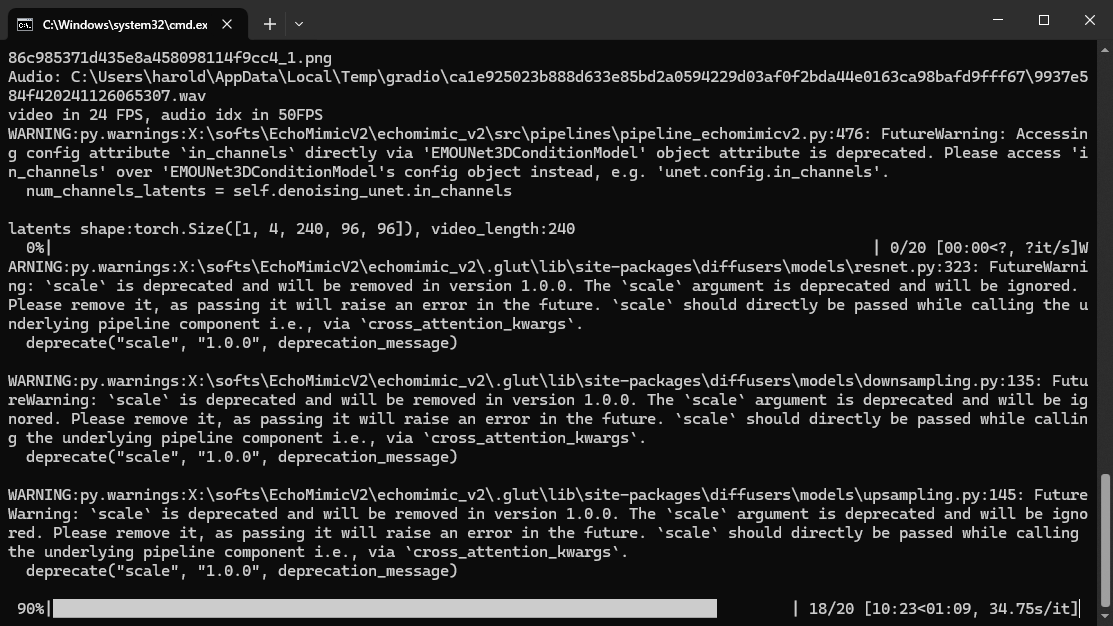
效果
秋叶ComfyUI便携版🔑
- 秋叶ComfyUI基础教程:查看
- 开启科学上网,注意,打开代理网络设置,然后
重启comfyUI
安装教程
注意
- 下面两种安装说明和教程
只为记录过程, - 直接从下载地址的
网盘下载启动包和模型文件,启动即可,无需再次安装
使用安装管理器方式
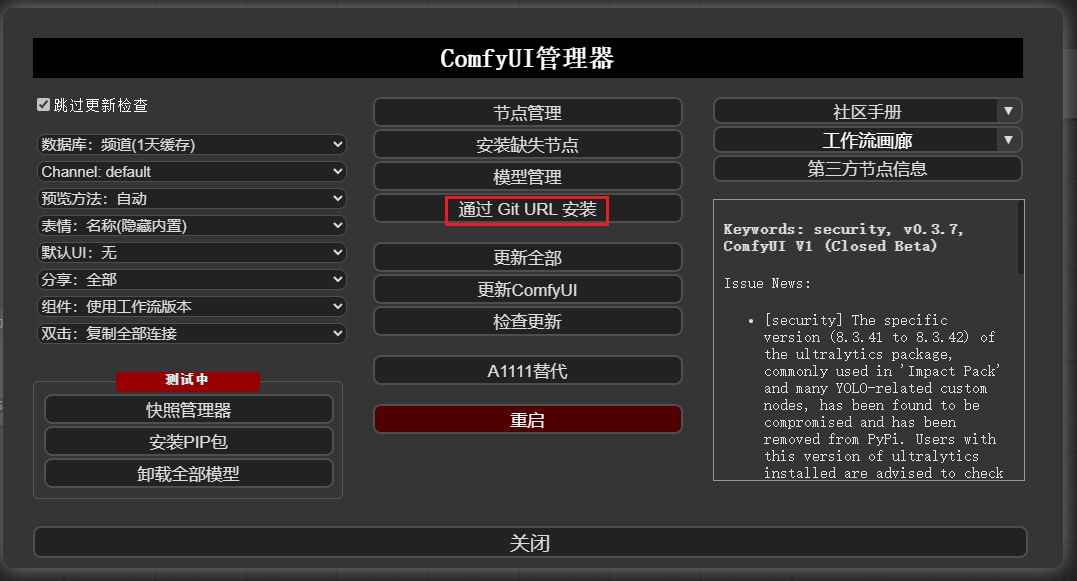
- 安装成功后,重启
ComfyUI
使用git仓库手动方式
- 如果安装管理安装有问题,可以使用手动方式
- 克隆仓库
# 进入comfyUI节点目录
cd custom_nodes
git clone https://github.com/smthemex/ComfyUI_EchoMimic
cd ComfyUI_EchoMimic- 使用
当前ComyUI环境的python进行安装(注意:不要直接使用python.exe)
# 当前ComfyUI环境的python
..\..\python\python.exe -m pip install -r requirements.txt
..\..\python\python.exe -m pip install --no-deps facenet-pytorch警告
- 如果安装
facenet-pytorch后comfyUI奔溃,可以先卸载torch,然后再重新安装,以下版本只是示例
# 先卸载torch相关包
..\..\python\python.exe -m pip uninstall torchaudio torchvision torch xformers
# 重新安装torch相关包
..\..\python\python.exe -m pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124
..\..\python\python.exe -m pip install xformers安装成功后,重启ComfyUI
模型下载
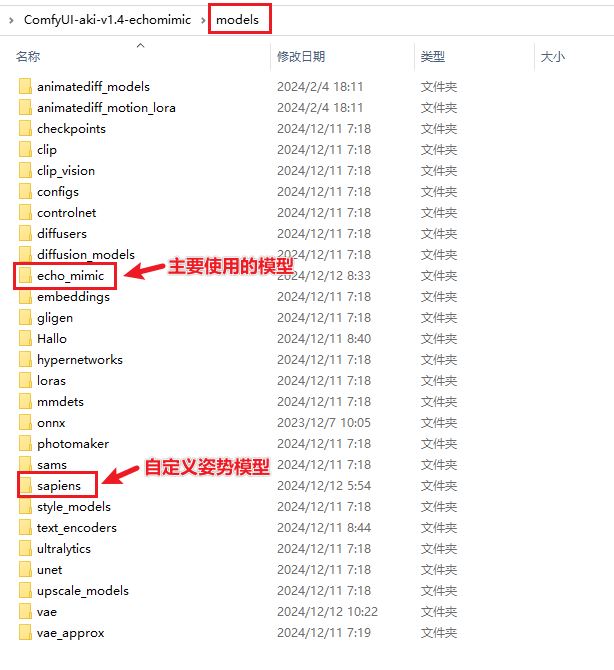
v1和v2共用的模型
建议
默认会自动从huggingface下载,可以开启huggingface代理镜像或设置hf-mirror镜像
如果访问不了,可以将https://huggingface.co/改为https://hf-mirror.com/
- unet模型下载地址:https://huggingface.co/lambdalabs/sd-image-variations-diffusers
- audio_processor:https://huggingface.co/BadToBest/EchoMimic/tree/main/audio_processor
- vae模型下载地址:https://huggingface.co/stabilityai/sd-vae-ft-mse
├── ComfyUI/models/echo_mimic
| ├── unet
| ├── diffusion_pytorch_model.bin
| ├── config.json
| ├── audio_processor
| ├── whisper_tiny.pt
| ├── vae
| ├── diffusion_pytorch_model.safetensors
| ├── config.jsonV1模型
├── ComfyUI/models/echo_mimic
| ├── denoising_unet.pth
| ├── face_locator.pth
| ├── motion_module.pth
| ├── reference_unet.pth- 音频驱动加速版
├── ComfyUI/models/echo_mimic
| ├── denoising_unet_acc.pth
| ├── face_locator.pth
| ├── motion_module_acc.pth
| ├── reference_unet.pth- 姿态驱动
├── ComfyUI/models/echo_mimic
| ├── denoising_unet_pose.pth
| ├── face_locator_pose.pth
| ├── motion_module_pose.pth
| ├── reference_unet_pose.pth- 姿态驱动加速版
├── ComfyUI/models/echo_mimic
| ├── denoising_unet_pose_acc.pth
| ├── face_locator_pose.pth
| ├── motion_module_pose_acc.pth
| ├── reference_unet_pose.pthV2模型
├── ComfyUI/models/echo_mimic/v2
| ├── denoising_unet.pth
| ├── motion_module.pth
| ├── pose_encoder.pth
| ├── reference_unet.pth- YOLOm8: https://huggingface.co/Ultralytics/YOLOv8/tree/main
- sapiens pose:https://huggingface.co/facebook/sapiens-pose-1b-torchscript/tree/main
Sapiens自定义手势🖐🏼
说明
由于目前绝大部分AI,对生成
手势图片或视频效果都不太好,可以使用一些现实主播、讲解视频的手势infer_mode
第一种,
infer_mode选择audio_drive,pose_dir选择none,则使用默认的npy pose文件,第二种,
infer_mode选择audio_drive,pose_dir选择已有的npy文件夹(位于ComfyUI/input/tensorrt_lite目录下),第三种,
infer_mode选择pose_normal,video_images连接视频入口,确认...ComfyUI/models/echo_mimic下有yolov8m.pt和sapiens_1b_goliath_best_goliath_AP_639_torchscript.pt2模型
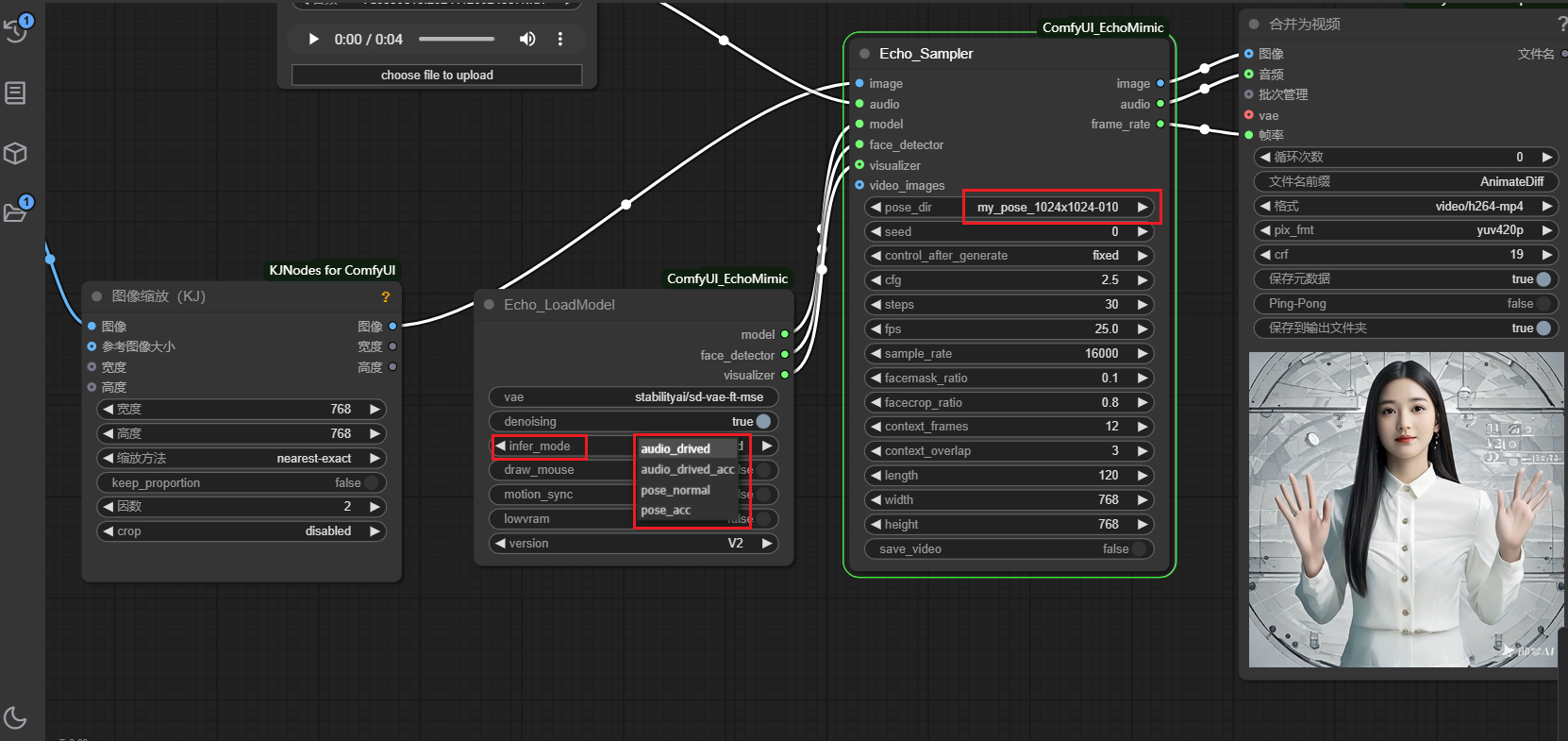
- 基于
COCOfullbody编码 ,单独使用pose模型时,可选pose的5种分离模式,分别是躯干,下肢,手,上肢,头部 - 对应选择seg_select 的编号分别是(
21.torso,4.Left_foot,5.Left_Hand,6.Left_lower_arm,3.Face_Neck),这5种也可以自由组合,全选默认输出所有pose;
克隆项目
# 进入comfyUI节点目录
cd custom_nodes
git clone https://github.com/smthemex/ComfyUI_Sapiens
cd ComfyUI_Sapiens安装依赖
# 当前ComfyUI环境的python
..\..\python\python.exe -m pip install -r requirements.txt- 重启
comfyUI
模型下载
只支持torchscript的版本,但是有多种模型可选,最好质量的是1b或者2B,如果模型选择全是none,会自动下载一个1B的seg,下载后不要改模型名字- seg:https://huggingface.co/facebook/sapiens-seg-1b-torchscript/tree/main
- pose:https://huggingface.co/facebook/sapiens-pose-1b-torchscript/tree/main
- depth:https://huggingface.co/facebook/sapiens-depth-1b-torchscript/tree/main
- normal:https://huggingface.co/facebook/sapiens-normal-1b-torchscript/tree/main
# 模型名称可能后续会更新变化,以上面模型地址里的名称为准
# sapiens目录如果不存在,则新建
├── ComfyUI/models/sapiens/
| ├── seg/sapiens_1b_goliath_best_goliath_mIoU_7994_epoch_151_torchscript.pt2
| ├── pose/sapiens_1b_goliath_best_goliath_AP_639_torchscript.pt2
| ├── normal/sapiens_1b_normal_render_people_epoch_115_torchscript.pt2
| ├── depth/sapiens_1b_render_people_epoch_88_torchscript.pt2识别手势
- 将
png文件拖到打开的Comfy UI界面中 - 说明:该
png文件中包含了workflow工作流
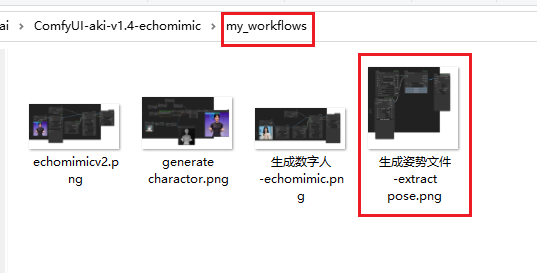
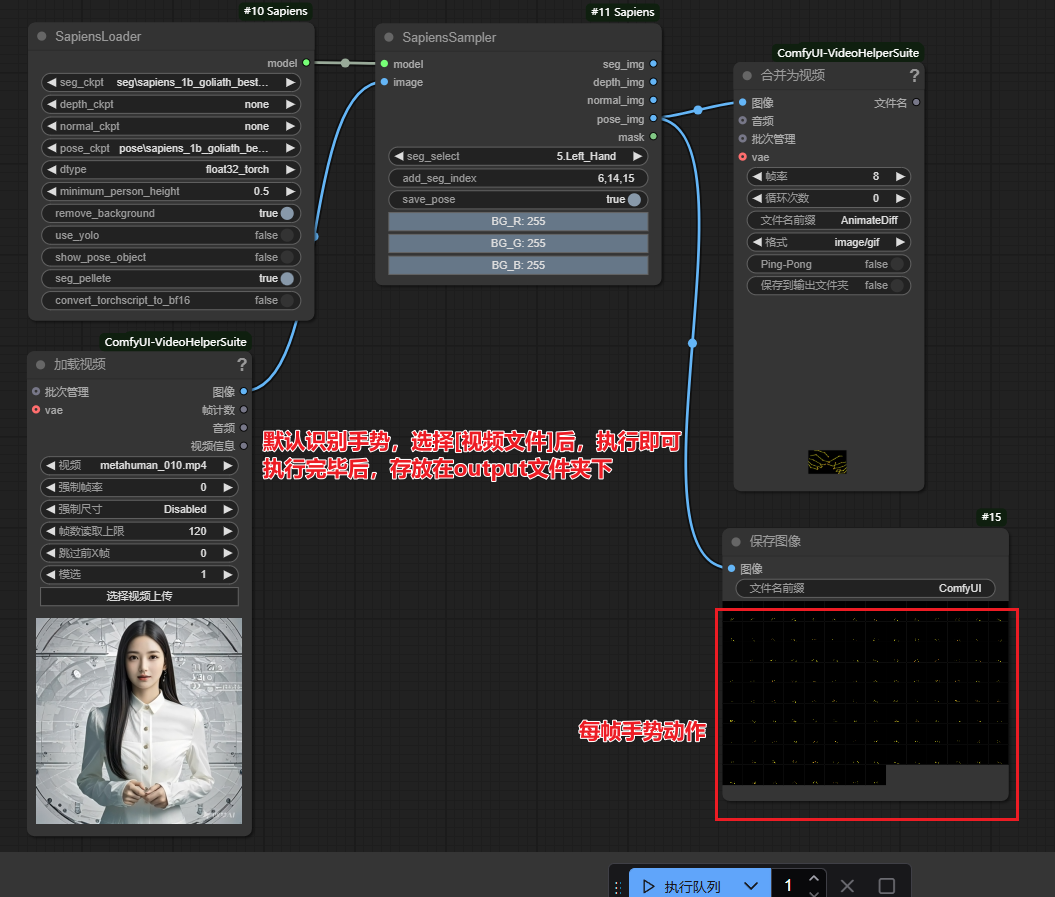
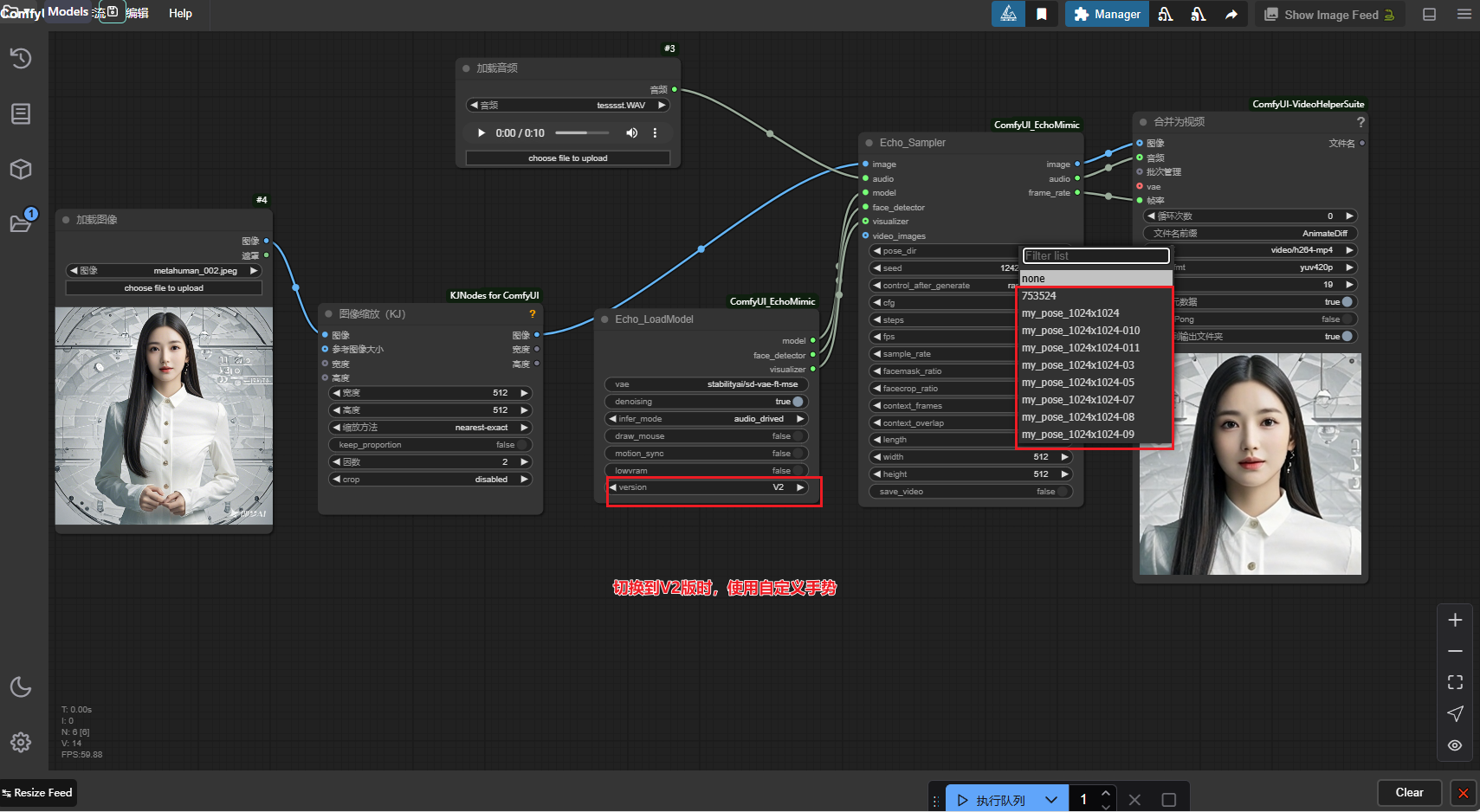
使用自定义手势
说明
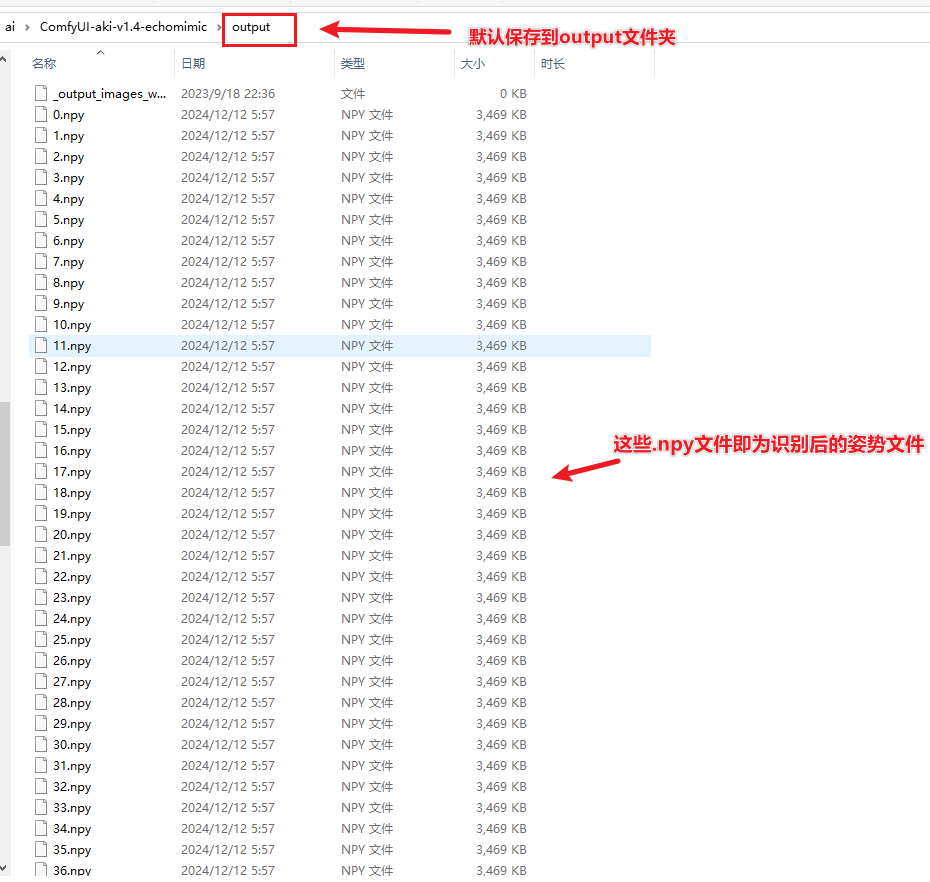
- 将上面识别出的
npy文件移动到ComfyUI/input/tensorrt_lite - 如果
tensorrt_lite文件夹不存在,就新建一个
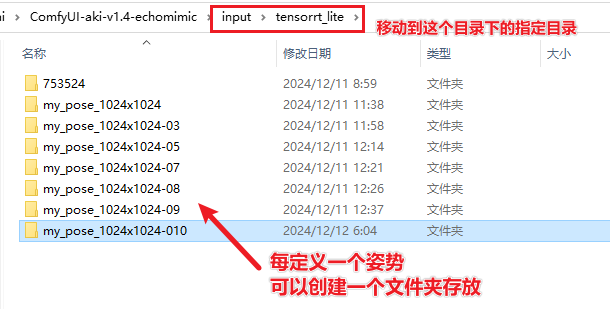
下载地址
建议
说明:
已安装相关
依赖、工作流以及模型文件为避免单个压缩包体积过大,几个大的模型分开单独文件夹上传到网盘
使用💻
注意
- 图片输出尺寸尽量为
768x768 - 图片输入和输出
尺寸要保持一致,否则可能会变形等情况 - 使用自定义
手势,原图片需要包含手部
- V1和V2版可以共用一个工作流
- 将
工作流拖到打开的web页面里

- 在工作流里切换
version,实现v1和v2切换使用
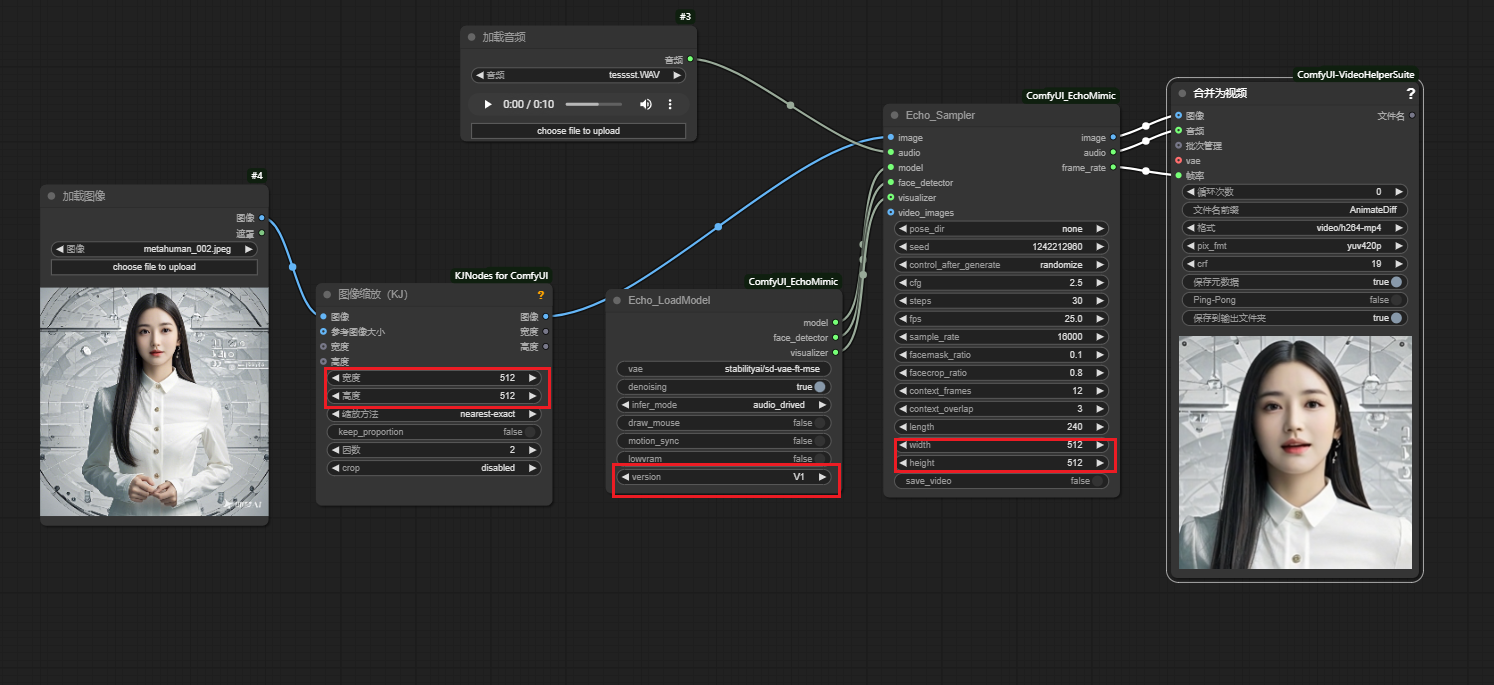
- 自定义
手势使用
更新历史
- 🔥🔥🔥我们发布我们的EchoMimicV2代码和模型。
🔥EchoMimic现在可以在带有A100 GPU的huggingface上使用。谢谢文萌Zhou@ModelScope。
🔥🔥🔥Audio Driven上的加速模型和管道发布。推理速度可以提高10倍(在V100 GPU上从~7分钟/240帧到~50/240帧)
- 🔥EchoMimic Gradio demo已准备就绪。
- 🔥Huggingface上的EchoMimic Gradio demo已准备就绪。谢谢你,西尔万Filoni@fffiloni。
🔥🔥🔥音频+选定地标上的加速模型和管道发布。推理速度可以提高10倍(在V100 GPU上从~7分钟/240帧到~50/240帧)
🔥ComfyUI现在可用。感谢@smthemex的贡献。
- 🔥感谢NewGenAI的视频安装教程。
- 🔥我们发布姿势和音频驱动的代码和模型。
- 🔥WebUI和GRadiUI版本发布,我们感谢@greengerong@Robin021和@O-O1024的贡献。
- 🔥我们的论文在arxiv上公开发表。
- 🔥我们发布我们的音频驱动代码和模型。